Self-Evolving Agents: The Emerging Stack and Field Insights
Artificial intelligence is entering a new epoch: systems are evolving from static reasoning engines into autonomous entities capable of open-ended self-improvement.
Earlier this year, Zhang et al. (2025) introduced the Darwin Gödel Machine, a meta-architecture for self-evolution guided by environmental feedback and meta-rewards. Its recursive design connects reflection, environment interaction, and reward modeling into a continuous evolutionary loop.
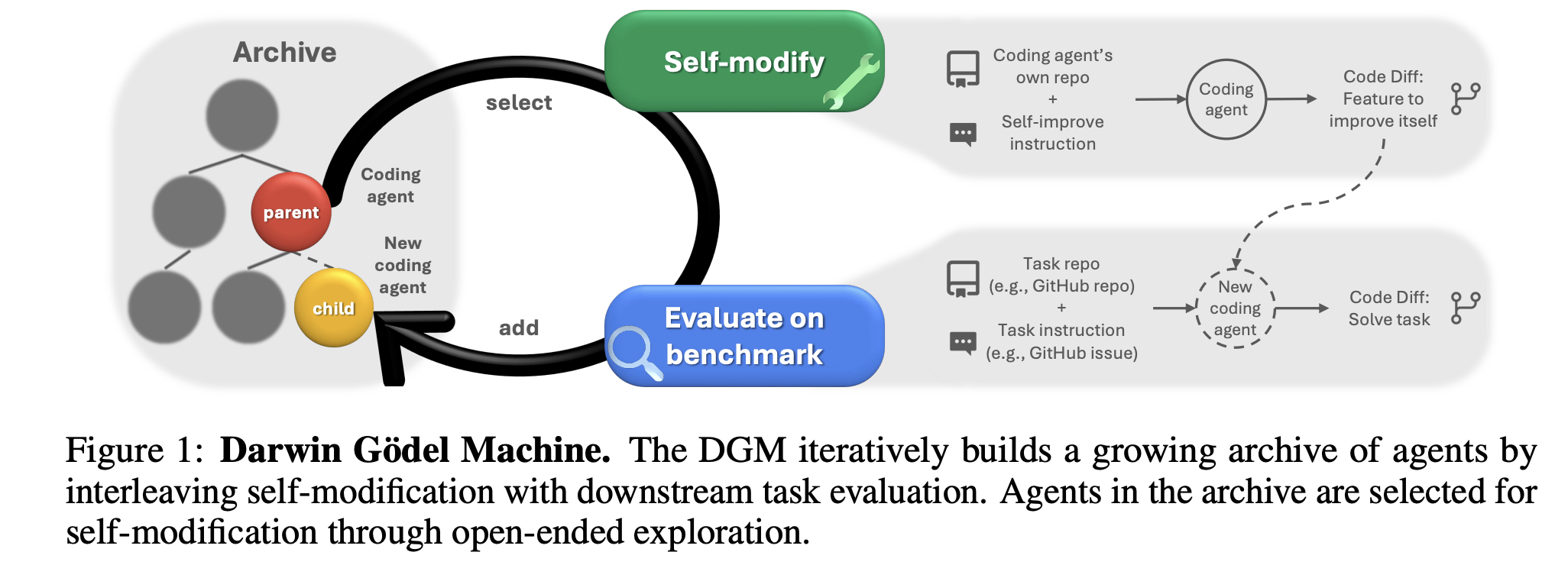
This theoretical milestone, once confined to academic speculation, now underpins a wave of commercial experimentation. Our core investment thesis is that the self-evolution stack will define the next platform era in AI.
At our recent hackathon, we convened 100+ builders and dozens of industry experts and researchers to test these ideas in practice. Across projects ranging from automated research assistants to adaptive coding agents, participants explored how feedback loops drive compounding intelligence.
From Research Framework to Investment Thesis
Fang et al. (2025) offer an abstraction of self-evolving systems. They describe four interacting components (System Inputs, Agent System, Environment, and Optimizer) and five optimization axes that define where adaptation occurs:
- Tool-Level Optimization: Learning when and how to call tools or APIs effectively.
- Memory-Level Optimization: Deciding what experiences to store, retrieve, or forget.
- Prompt-Level Optimization: Adjusting context and instruction structure dynamically based on performance.
- Policy-Level Optimization: Updating the model's internal decision policies through outer-loop fine-tuning, self-rewarding, or reinforcement learning.
- Environment-Level Optimization: Modifying or generating the environment itself to improve feedback quality and curriculum design.

Their insight reframes "self-evolution" not as a single algorithm but as a closed feedback system. Systems that can autonomously generate, evaluate, and integrate new experiences will compound faster than any static model. The "outer loop" of self-improvement (e.g., reflection, environment design, and self-rewarding) becomes the key source of differentiation.
In tandem, we will see accelerated growth in infrastructure layers that can consolidate around agent OS layers and provide efficient means to close this "outer loop." We will also see domains like biomedicine, software development, and enterprise automation–all of which are inherently feedback-rich–become early winners of the self-improvement paradigm shift. Agents that can leverage real-world outcomes as training signals (e.g., clinical accuracy, code correctness, business KPIs) will dominate their verticals.
The long-term frontier is meta-learning infrastructure: systems that make the process of evolution itself programmable. This framework anchors our belief that the self-evolution stack will define the next platform era in AI.
The Stack
The Foundation Model Layer: The Engines of Evolution
The foundation model is no longer a passive reasoning core; it is the substrate of evolution. Providers are rapidly vertically integrating their offerings to serve different evolutionary niches within the self-evolving-agent paradigm. The key question becomes which model will provide the most reliable, feature-rich, and economically viable backbone for agentic systems.
The market also see a pragmatic bifurcation between two types of model providers:
- Closed Models Win for Production Reliability: Teams building revenue-generating agents prioritize the reliability, lower latency, and advanced, agent-specific features (e.g., tool use, safety) of proprietary models.
- OSS Models Win for Research & Control: Teams focused on deep research, cost management, or building highly differentiated, fine-tuned systems gravitate toward open-source models like Llama and Mistral.
Closed-Source Models
| Provider | Model | Key Traits |
|---|---|---|
| OpenAI | GPT | Mature tool/function calling & structured outputs. Best-in-class tool-calling and structured function-execution via JSON schemas enable reliable multi-step reasoning. Its Assistants API provides persistent memory and file-handling. |
| Gemini | Native multimodality (text–audio–vision; Multimodal Live API) and Workspace integration (Gmail/Docs/Drive/Chat), plus Agent/Agent Mode & Computer Use previews for automation. This makes Gemini well-suited to perception-action loops and enterprise workflows where agents must see, reason, and act across Workspace. | |
| Anthropic | Claude | Very long context (up to ~1M tokens in beta/enterprise channels) enabling deep code/document analysis and longer reflective chains—useful for agent planning/verification over long horizons. Strong safety/constitutional methods. |
| Cohere | Command | Enterprise-oriented stack with emphasis on retrieval (Embed/Rerank), privacy, and deployment flexibility; positioned for agent workflows that require verifiable, governed RAG and corporate data integration. |
OSS Models
| Provider | Model | Key Traits |
|---|---|---|
| Meta AI (FAIR) | LLaMA | The de facto open-weight backbone for agent projects, benefiting from a massive community and permissible licensing. Research from leaders like Yann LeCun champions self-supervised learning, fueling the open, autonomous AI paradigm |
| Mistral AI | Mistral-8x22b | Sparse MoE (39B active of 141B total) gives strong cost-efficiency and latency for self-hosted agents; popular for organizations wanting control over fine-tunes/infra. |
| Others | Qwen, Grok, ERNIE | Alternative architectures and training data mixes |
From RLHF to Continuous Self-Rewarding
Today, evolution happens in the outer loop–by optimizing memory, tools, and policies–while the foundation model acts as a fixed reasoning engine. However, beyond the outer loop, there is a not-so-distant future in which "self-evolution" implies models rewriting their own weights.
The current paradigm of Reinforcement Learning from Human Feedback (RLHF) uses a static reward model trained on human preferences. The future is a shift toward Self-Rewarding Language Models, where the model itself acts as the judge, providing its own rewards to continuously fine-tune its policy. This is the commercial realization of research concepts like the Self-Challenging Agent (SCA) (Zhou et al., 2025).
Experience Generation Becomes a Core Capability
Foundation models are becoming powerful enough to generate their own training data, effectively creating their own curriculum. Google's emphasis on synthetic data generation with Gemini 2.0 is a key industry signal in this direction, enabling models to bootstrap their capabilities in new domains where real-world data is scarce. This aligns with research like AgentGen (Hu et al., 2025), where agents construct their own simulation worlds to drive learning.
Next-Generation Model Features We're Watching
- Computer-Use Agents Are Racing to Automate Real-World Workflows. Several providers now offer browser/desktop-control agents enabling feedback-rich loops: Google's Gemini 2.5 Computer Use integrates tightly with Workspace and automates multi-step tasks by transforming screenshots into actions; Anthropic's Claude Computer Use lets teams auto-operate VDI environments with long-context reflection and audit logs; and OpenAI's Computer-Using Agent (Operator) combines GPT-4o vision with RL-trained UI control (still in research preview).
- Structured Tool Calling Becomes the Interface for Learning. OpenAI's Responses API and Agents SDK formalize tool use as a native operation—each invocation a typed, traceable event that doubles as feedback data for future learning. Google's Gemini API follows a similar path with explicit JSON-schema function calls integrated across Workspace and Vertex, turning enterprise workflows themselves into measurable trajectories.
- Persistent Memory Turns Sessions into Lifetimes. Anthropic's Claude Memory and OpenAI's persistent Threads (via the new Responses API) are pioneering the shift from stateless chat to long-term continuity.
- Realtime Multimodality Accelerates Feedback Density. OpenAI's Realtime API and Gemini's Multimodal Live API both support low-latency, bidirectional multimodal I/O (speech/audio + text, and Live supports video).
- Enterprise-Grade Deployment Enables Safe Experimentation at Scale. Claude is available via Anthropic's API, Amazon Bedrock, and Google Vertex AI, while OpenAI models are offered through Azure OpenAI—a combination that lets enterprises run controlled A/B tests and policy updates with governance (e.g., CloudTrail on AWS, enterprise controls on Azure). Cohere extends this posture with private VPC / on-prem options for compliance-bound workloads where reward signals must be logged and audited safely.
- Standardized Agent APIs Lay the Groundwork for Outer-Loop Automation. Emerging SDKs like OpenAI's Agents and Google's Agent Mode are beginning to expose hooks for tracking trajectories, success rates, and outcomes.
Tools and Frameworks
Agent Orchestration & Planning
The orchestration framework is responsible for planning, state management, and coordinating the complex, multi-step workflows that define agentic behavior. Seminal open-source projects like AutoGPT (Yang et al., 2023) first proved the potential of autonomous agents, and influential research like Microsoft's AutoGen (Wu et al., 2024) pioneered multi-agent conversational patterns.
Modern frameworks provide infrastructure to enable the "outer loop" of self-evolution. The commercial landscape has rapidly matured toward robust, production-grade platforms.
The Agent OS Will Be Stateful, Evaluated, and Pluggable
The core investment thesis is that the company that provides the dominant "operating system" for agents (analogous to web frameworks like Ruby on Rails for Web 2.0) will capture immense value by becoming the default execution layer. Early chains proved agents could act; the winners will natively manage state, surface evaluations/telemetry, and plug into any model, tool, and environment.
There is strong market activity here, as evidenced by the proliferation of frameworks and LangChain's recent $1.25 billion valuation.
| Category | Key Players | Strategic Positioning |
|---|---|---|
| Open-Source Incumbents | LangGraph AG2 (OSS branch of Microsoft AutoGen) LlamaIndex CrewAI Mastra (Sam Bhagwat) |
First-Mover Advantage & Ecosystem: LangChain and LlamaIndex have massive developer adoption. LangGraph's stateful, graph-based architecture is becoming the standard for building production agents, while LlamaIndex is known for its advanced RAG techniques. CrewAI simplifies multi-agent systems. Mastra AI, with its $13M seed, works in the TypeScript/JavaScript developer community |
| First-Party Challengers | OpenAI AgentKit Google ADK Microsoft Agent Framework (formerly AutoGen) |
Native Integration & Simplicity: These frameworks offer seamless integration with their respective foundation models (GPT-5, Gemini). They are positioned as the simplest path to build agents on their platforms, often with visual builders that compete with Zapier. Key players aim to be the fastest path to production on their model stacks (tight function calling, hosted eval hooks, computer use). Expect continued consolidation around "one-vendor" developer flows for teams that prize speed over portability. |
| Enterprising and Low-Code | Flowise (acquired by Workday) LangFlow (acquired by DataStax) Dust Griptape |
Enterprise & low-code expand the surface area: Enterprise-focused platforms like Dust and Griptape differentiate on governability (RBAC, policy, observability). Visual builders like Flowise and LangFlow broaden access; they are useful for prototyping and internal automations, then handing off to code-first orchestration. |
Stateful, Multi-Agent Graphs Redefine Orchestration.
Early agent frameworks executed linear, stateless chains. The next generation manages branching logic, persistence, and collaboration among specialized agents. LangGraph leads this shift with a graph-based execution model that treats every node as a resumable state machine, while Microsoft's AG2 (AutoGen OSS) and CrewAI extend the pattern to conversational and role-based teams. OpenAI's Agents SDK and Google Agent Mode are following suit, introducing native session state and coordination hooks inside their model runtimes.
Learning Loops Become Native to the Framework.
Today, evaluation and fine-tuning happen in disconnected MLOps stacks; tomorrow's orchestrators will capture agent trajectories, score them, and trigger updates directly. W&B Weave and LangSmith already provide integrated tracing and multi-turn evaluation; OpenAI's Responses API and Google Agent Mode formalize step-level telemetry that can be analyzed or rewarded in real time.
Self-Modifying Orchestration Extends the Outer Loop.
Longer term, orchestration frameworks will evolve from static graphs to self-improving programs. Inspired by the Darwin Gödel Machine concept, agents will propose and test edits to their own workflows under audit constraints, creating a recursive optimization loop. LangGraph and AG2 provide natural foundations because their declarative graphs can be diffed, versioned, and rolled back, while evaluation platforms such as Weave or LangSmith supply the safety rails for testing orchestration changes.
Tools and Skills
Tools allow agents to interact with the outside world, execute tasks, and, most critically for self-evolution, generate the feedback necessary for improvement.
The core investment thesis is that value will accrue to platforms that create liquid interfaces to the digital and physical world. This means moving beyond static connectors to dynamic systems where agents can discover, combine, and even create tools, a frontier that was opened via seminal research like ToolLLM (Qin et al., 2023) and Voyager (Wang et al., 2023). The market is evolving from a simple "Zapier for AI" model to a more sophisticated, multi-layered ecosystem for action, safety, and feedback.
Notably, we also observe the beginnings of vertical integration between tools and orchestration solutions. A prime example is OpenAI's approach with AgentKit: by tightly coupling the orchestration layer (AgentKit) with a curated set of tools and their flagship model (GPT-5), OpenAI is creating a "lock-in layer."
| Category | Description | Key Players |
|---|---|---|
| API and Skills Layer | Provides the connective tissue between the agent's reasoning and external APIs | Composio: An "agent-native" tool library with a focus on creating a reliable "skill layer" for agents. Pipedream: Ships managed MCP servers that instantly expose ~3,000 APIs and ~10,000 tools to the agent Hugging Face Transformers Agents: A standardized open-source interface for calling thousands of models as tools. Stability AI: A specialized creative tool for on-demand image, audio, and video generation Gumloop, Make.com, Workato: Established and emerging iPaaS platforms providing thousands of connectors for enterprise automation MCP in IDEs: Anthropic's Model Context Protocol is becoming the standard way to plug tools/data into agents; IDEs are shipping MCP clients (e.g., JetBrains IntelliJ 2025.1), making "use the codebase/CI/ticketing tool" a first-class, in-editor capability. Amplitude also ships an MCP server to expose product analytics as an agent tool |
| Secure Execution Layer | Creates a safe "sandbox" for agents to execute code or perform actions without risking harm to the host system | Daytona: A high-speed, open-source sandbox for running AI-generated code. E2B: An "enterprise AI agent cloud" providing secure, tool-equipped cloud environments for agents. Runloop: A runtime environment for agents designed to manage continuous loops, checkpointing and rollback Modal: Serverless compute platform that supports persistent containers triggered by agents, with built-in autoscaling and native Python decorators for lightweight sandboxing Microsandbox: An open-source alternative focused on lightweight, secure code execution |
| Feedback and Reward Layer | Translates the outcome of an agent's actions into a measurable signal for learning and evolution | Amplitude MCP: Exposes product analytics as a reward signal, allowing agents to query their own performance. Livekit: Provides real-time voice/video infrastructure, enabling feedback for multimodal and embodied agents. Langfuse, Arize, W&B Weave,Monte Carlo: Agent observability platforms that trace agent behavior, providing the raw data for reward modeling |
Automated Tool Discovery and Composition
Today, developers manually select and wire up tools. The next step is for agents to do this themselves. Frameworks will evolve to allow agents to dynamically discover relevant tools from a vast library based on the task at hand, and even compose multi-tool chains on the fly. This is the commercial application of research like ToolLLM (Qin et al., 2023), which studied how LLMs could learn to master over 16,000 real-world APIs.
From Tool Calling to Tool Creation
The ultimate frontier is moving beyond using existing tools to creating new ones. Inspired by research like ToolGen (Wang et al., 2024), future agents will be able to read API documentation and write their own functions or "skills" to interact with new services they've never seen before.
Convergence of Observability and Reward Modeling
The "Feedback & Reward Layer" will become more sophisticated. Platforms like Langfuse and Arize, which currently focus on observability (tracing agent behavior), will increasingly merge with reward modeling. Instead of just showing what an agent did, they will provide tools to define what success looks like for that action.
Next-Generation Features We're Watching
- MCP Becomes the Default Tool Interface. As IDEs like JetBrains adopt MCP clients and analytics platforms such as Amplitude ship MCP servers, tool discovery and invocation become standardized, authenticated, and observable. Anthropic's MCP ecosystem anchors the standard, while JetBrains' developer footprint and Amplitude's analytics hooks demonstrate its reach beyond model labs into everyday enterprise software. Pipedream extends the ecosystem horizontally, exposing thousands of APIs through managed MCP servers and turning tool catalogs into a network effect.
- Sandbox-First Execution Becomes Table Stakes. Sandboxes now define the security, speed, and auditability of every agent action. We're particularly bullish on Daytona, which has demonstrated above-market rate limits, reliability, and developer support.
- Data Ingestion Converges with Evaluation. The boundary between "context" and "feedback" is collapsing. Pipelines that once served static knowledge—like Firecrawl's web ingestion or Amplitude MCP's analytics feeds—are beginning to stream labeled events directly into evaluation and reinforcement buffers. Every click, conversion, or error becomes a datapoint for the learning loop.
- Tool Catalogs Turn into Skill Markets. The open tool ecosystem is evolving from static listings into competitive marketplaces governed by trust, provenance, and success rates. Composio's "agent-native" skill layer and Pipedream's expansive app catalog are already layering telemetry (tracking uptime, safety scores, and usage frequency) to let agents choose tools based on performance rather than hard-coded preference.
- Computer-Use Agents Close the Loop on Human Workflows. Browser and desktop control is becoming the frontier for embodied digital labor. OpenAI's Operator (built on GPT-4o and the Responses API), Google's Gemini Computer Use, and Anthropic's Claude Computer Use all translate visual input into structured, auditable actions.
Memory and Vector Databases
The memory layer is the stateful repository where an agent stores and retrieves knowledge, experiences, and skills. Foundational research like Reflexion (Shinn et al., 2023) established that an agent could improve its performance by storing and critiquing its own reasoning–turning memory into an active tool for self-improvement.
The research frontier is focused on moving beyond simple data stores to more cognitively-inspired systems. This includes implementing structured long-term memory via knowledge graphs and developing sophisticated short-term memory curation, such as using the Ebbinghaus forgetting curve to intelligently decide which memories to retain or let decay, as explored in frameworks like MemoryBank (Zhong et al., 2024). ReasoningBank (Google, 2025) worked towards "lifelong reasoning memory" and a persistent, queryable repository of experiences.
For a self-evolving agent, this layer is the experience repository that fuels the "outer loop" of learning. The dominant paradigm for agentic memory today is Retrieval-Augmented Generation (RAG). A common example of RAG implementation is pairing a vector database with an LLM to provide a long-term memory that extends beyond the token-limited context window.
The core investment thesis is that as agents become more autonomous and long-running, the value of their accumulated experience will grow exponentially. The frontier now extends to memory that writes itself, forgets selectively, and learns what to remember.
| Category | Description | Key Players |
|---|---|---|
| Vector Databases | The underlying database technology that stores information as high-dimensional vectors (embeddings) for fast, semantic retrieval. | Pinecone: The venture-backed market leader, known for its managed, high-performance vector search service. Weaviate: A strong open-source and EU-based competitor to Pinecone. ChromaDB, Milvus, Qdrant: Popular open-source alternatives that offer more control and are often self-hosted. |
| RAG and Knowledge Frameworks | The "operating system" for RAG, providing the tools to ingest data from diverse sources and build queryable knowledge indexes. | LlamaIndex: market leader in composable RAG systems LangChain RAG: integrated within orchestration stacks KnowledgeGPT, AG2 Memory components: emerging players |
| Data Ingestion and Processing | The "plumbing" that crawls, cleans, and structures raw data (from websites, documents, etc.) into an "LLM-ready" format for ingestion into a vector DB. | Firecrawl: Crawls websites and converts unstructured content into clean, structured data for RAG pipelines Reducto: Text distillation layer that compresses and summarizes raw documents into vector-optimized storage Unstructured.io, Airbyte: Other key players in the broader data integration and preprocessing space. |
| Agentic Memory Developer Tools | Lightweight, model-agnostic memory SDKs that let developers attach persistent context, episodic recall, and vector search to agents | Mem0: memory-as-a-service with automatic summarization and decay Supermemory: open-source memory graph for LLM agents Letta:TypeScript framework for stateful agents Zep: fast, embeddable vector memory for chatbots Hyperspell: semantic recall and personalized context memory |
| AI Browsers and Enterprise Memory Systems | Tools that unify search, documents, and conversational memory into knowledge graphs | Glean: enterprise knowledge graph and retrieval layer) Rewind: personal memory and timeline for local workflows Perplexity Pro Search: knowledge-grounded conversational memory Dex: local-first agent memory built into a browser-based context engine |
Next-Generation Features We're Watching
- From Vector Blobs to Structured Knowledge (Hybrid RAG): Simple vector search can lack precision. The next frontier is Hybrid RAG, which combines the semantic search capabilities of vector databases with the structured, explicit relationships of knowledge graphs. LlamaIndex is already heavily investing in this area.
- Intelligent Memory Curation & Forgetting: Infinite recall is inefficient. Future systems will adopt cognitive heuristics—ranking experiences by recency, salience, and utility—to balance cost and relevance. Frameworks like MemoryBank experiment with forgetting curves and self-pruning vectors, while mem0 and Supermemory are pioneering automated summarization and decay policies that maintain signal-to-noise over long agent lifetimes.
- Memory as a Developer Primitive: Memory will no longer be bolted on through external databases; it will become a native SDK abstraction. Tools like Letta and Zep already embed episodic recall into the agent runtime itself, turning "state" into a first-class feature. Expect orchestration frameworks (LangGraph, AgentKit) to adopt memory modules that unify short-term context, long-term recall, and reflection histories into one interface.
- The "Memory-Compute" Trade-off and Active Retrieval: Retrieving from large memory stores is computationally expensive; recomputing may often be cheaper. Future agent systems will learn this tradeoff dynamically, programmatically deciding when to recall versus regenerate. Platforms like Modular and OctoML will likely play a role in optimizing these retrieval economics at runtime.
- Knowledge Graphs Meet Personal Context: As enterprise knowledge systems (e.g., Glean) and personal context platforms (e.g., Rewind) merge with LLM agents, we'll see hybrid memories that span organizational and personal domains. These graphs will evolve into shared cognitive substrates, where agents learn collaboratively across users and teams, creating an emergent "collective memory" layer of the self-evolution stack.
Prompt and Context Engineering
While early efforts focused on manual "prompt engineering," this is a rapidly commoditizing skill. The investment thesis is that value is shifting to programmatic context optimization, where the system itself learns and refines the most effective context for a given task.
This is the shift from "prompt engineering" to what Anthropic calls "context engineering"–treating context as a critical, finite resource to be algorithmically managed. The academic blueprint for this is the Agentic Context Engineering (ACE) framework from Stanford and SambaNova (2025), which treats context as an "evolving playbook" that the agent refines over time.
In our opinion, the prompt/context engineering space will collapse into the memory optimization space. Still, recent activities in the prompt optimization space include:
- Vellum: A venture-backed enterprise platform for prompt A/B testing, versioning, and systematic evaluation, which recently raised a $20M Series A.
- DSPy: A powerful open-source framework from Stanford that treats prompting as a programming problem, automatically optimizing prompts and model weights.
In the near future, we will see a convergence with orchestration via Agentic Context Engineering. The prompt will evolve from a static block of text into a dynamic, executable program.
Evaluation and Feedback
This layer provides the "reward function" for the agent's learning loop. Foundational research has established the outer-loop optimization principle: models can continuously refine themselves using feedback generated from their own behavior, not just static datasets.
This principle was pioneered by concepts such as LLM-as-a-Judge (Zheng et al., 2023), and was further advanced by Self-Rewarding Language Models (Yuan et al., 2024), which proved that an agent could generate tasks, produce solutions, and then grade its own performance to create an automated feedback loop. Complementary work like TextGrad (Yuksekgonul et al., 2024) and AutoRule (Lyu et al., 2025) has focused on converting qualitative feedback into structured, differentiable reward signals.
As agents move into production, the commercial layer is coalescing around systems that operationalize this principle: capturing, structuring, and applying feedback at scale. The next generation of evaluation frameworks treat every interaction as an experiment, or an opportunity to quantify and reinforce improvement.
| Category | Description | Key Players |
|---|---|---|
| Experiment Tracking and Observability | The "Datadog for AI," providing tools to trace, log, and compare agent behaviors over time | Weights & Biases (W&B): The market leader in MLOps, now extending its platform with Weave to provide first-class support for tracing and evaluating agentic workflows Ruler (OpenPipe): lightweight evaluation and scoring framework enabling structured prompts, reference outputs, and metric computation directly in production pipelines Haize Labs: emerging leader in feedback data infrastructure and reward model training, building platforms for collecting, curating, and aligning AI and human feedback at scale |
| Safety and Guardrails | Ensures agent outputs are safe, reliable, and adhere to predefined rules before being executed | Guardrails AI: An open-source and commercial platform for enforcing structural and quality guarantees on LLM outputs Lakera, ProtectAI: emerging contenders in model integrity and red-teaming for production agents |
| Benchmarks and Environments | Provides standardized, realistic environments for testing and comparing agent performance on complex tasks. Still primarily academic | WebArena & OSWorld: Influential open-source benchmarks that simulate complex web browsing and operating system tasks, pushing the frontier of agent capabilities |
Future Directions:
- From Human Feedback to AI Feedback (RLAIF): The bottleneck of human-in-the-loop evaluation (RLHF) is being replaced by Reinforcement Learning from AI Feedback (RLAIF) (Lee et al., 2023). In this paradigm, a powerful "judge" model provides the reward signal. OpenAI, Anthropic, and DeepMind are converging on this paradigm, with Ruler and Weave positioned to operationalize automated scoring pipelines at production scale.
- Real-World KPIs as Reward Signals: Evaluation is shifting from synthetic metrics to grounded business outcomes. Agents may directly query business intelligence tools (like Amplitude MCP) or production databases to measure their own impact on KPIs, using metrics like "customer conversion rate" or "revenue generated" as their primary reward signal.
- Convergence of Safety and Evaluation: Safety guardrails and performance evaluations will merge. Instead of being a simple pass/fail check, a safety violation (e.g., generating toxic content or incorrect code) will become a strong negative reward signal. Guardrails AI is well-positioned to lead this convergence.
- Differentiable Feedback at Runtime: New frameworks like TextGrad push beyond scalar scores, converting textual feedback and logs into continuous learning signals. This unlocks near-real-time adaptation: agents that not only receive critiques but translate them into gradient updates without retraining.
Learning Environments
The Learning Environment is distinct from a simple sandbox; it is a persistent, high-fidelity simulation or digital twin of a real-world process that provides the rich, continuous feedback necessary for RL and self-improvement.
However, this layer is the least commercially developed. The market is bifurcated: frontier labs such as OpenAI, Anthropic, and Google build proprietary internal environments to train and benchmark their foundation models, while independent startups face the structural challenge of competing with in-house infrastructure.
Still, a nuanced investment opportunity is emerging. Despite these challenges, we see validation by a handful of high-conviction, early-stage bets. In our belief, the next decade's winners are unlikely to win by building synthetic "universes" from scratch—but it may be that a company may find early environment-building success that ultimately paves the way to a larger generational win.
| Category | Description | Key Players |
|---|---|---|
| "Gym for Agents" Platform | Provide a turnkey, infrastructural layer for environment creation, simulation, and synthetic data generation. The goal is to become the default "gym" where developers train their agents. | Applied Compute: A pre-launch, ex-OpenAI team that raised a significant round to build RL-as-a-Service infrastructure. Mechanize: Building RL environments that simulate white-collar work to sell to leading AI labs. |
| Domain-Specific Digital Twin | Focus vertically on a single, high-value domain (e.g., drug discovery, financial trading) where a specialized, integrated agent-and-environment stack can prove clear ROI. | Biomedical Agents (e.g., MedAgentSim): The most promising vertical, where a simulated clinical environment can train diagnostic agents with clear success metrics. Robotics (e.g., Google's RT-X): Using high-fidelity simulators to train robots before deploying them in the physical world. |
| Productized Learning Loop | Abstract away the "environment" and instead sell a "continuous learning" product to enterprises. This bundles a lightweight simulation with observability and feedback tools, tying agent evolution directly to business KPIs. | This is the most commercially viable near-term thesis. It's less about building a complex world and more about instrumenting the existing one. Amplitude MCP turns product analytics into a direct reward signal for the agent's learning loop. |
Future Directions:
- From Synthetic Worlds to Instrumented Workflows. Most real-world intelligence emerges not from richer simulation, but from denser feedback. The next generation of learning environments will blur the line between "sim" and "prod," where live applications, analytics systems, and telemetry streams become continuous RL environments.
- Verticalized Environments Will Anchor Early ROI. In healthcare, finance, and robotics, digital twins provide the clearest pathway to measurable outcomes. Biomedicine remains the strongest vertical thesis: simulated clinical settings offer safe, data-rich domains for agent evaluation and fine-tuning. Robotics follows closely, where simulation-to-reality transfer is already a proven research frontier.
- Simulation Infrastructure Will Converge with Evaluation. Tools like Mechanize and Applied Compute are effectively evolving into evaluation platforms, offering fine-grained control of task difficulty, outcome scoring, and reward shaping. Over time, these systems will merge with observability and RL pipelines.
- The Long-Term Frontier: Self-Constructing Environments. Inspired by research like AgentGen (Hu et al., 2025), agents will eventually construct their own training environments, generating synthetic worlds to probe weaknesses and create new challenges autonomously.
Applications and Use Cases
Verticals like biomedicine and software development are characterized by specialized task structures, unique data modalities, and operational constraints that demand tailored agent architectures. The investment thesis is to favor domains where agent behavior can be aligned with these procedural requirements and where success can be measured by clear, closed-loop feedback signals (e.g., clinical outcomes, tests pass/fail, conversion metrics).
Biomedicine
The biomedical domain is a prime vertical for self-evolving agents because it requires agents to operate under uncertainty, engage in multi-turn diagnostic dialogues, and integrate external knowledge bases.
Diagnostic Copilots & Virtual Clinicians
Ambient scribing is the beachhead; longitudinal reasoning with AI-powered diagnostic assistants is the destination. Research like MedAgentSim (Almansoori et al., 2025) provides the blueprint for training these agents in high-fidelity simulated environments, while commercial players are already attracting massive valuations. Abridge raised a large round in early 2025 to expand ambient AI across health systems, while Nabla has continued rolling out its "Copilot" in EHR workflows.
Key Players:
- Abridge, Nabla: leaders in clinical documentation, with a clear path to evolve their tools from passive scribes to active diagnostic partners.
- Hippocratic AI: focused on building safety-focused, patient-facing agents
- Glass Health: building a platform for AI-assisted clinical reasoning
Molecular Discovery & Autonomous Labs
In drug discovery, agents are being used to navigate the vast chemical space to find novel therapeutic compounds. Research like CACTUS (McNaughton et al., 2024), equipping agents with cheminformatics tools, and STELLA (Jin et al., 2025), a self-evolving agent for biomedical research, are the academic precursors to the commercial work.
Key Players: Insilico Medicine (IPO announced), Atomwise, and the publicly-traded Recursion, which operate closed-loop RL environments that connect LLM reasoning with wet-lab validation.
Future Directions:
- From Simulation to Real-World Clinical Data: The next step is to train agents directly on anonymized, real-world clinical data and patient outcomes.
- Multi-Agent Diagnostic Teams: Future systems will involve teams of specialized agents (e.g., a "radiologist" agent, a "pathologist" agent) that collaborate to arrive at a diagnosis.
Software Development
Software development is an ideal domain for self-evolving agents because its workflows are highly structured and it offers an unambiguous, binary feedback signal: code either works or it doesn't. Agent optimization in this domain is focused on aligning with established software engineering practices for code refinement and debugging.
Research is bifurcated in two main approaches:
- Self-Feedback Mechanisms: Research like Self-Refine (Madaan et al., 2023) and CodeCriticBench (Zhang et al., 2025) focuses on agents that can critique and revise their own code, creating a tight, autonomous feedback loop.
- Experience-Driven & Collaborative Workflows: Papers like AgentCoder (Huang et al., 2023) and CodeAgent (Zhang et al., 2024) simulate a development team by assigning specialized roles (coder, reviewer, tester) to different agents, which then collaborate to improve code quality.
Key Players: Sourcegraph Cody and Codeium are building "continuous improvement" assistants that learn from an entire codebase. Augment Code is explicitly focused on multi-agent "coder/reviewer/tester" orchestration.
Future Directions:
- From Code Assistant to Autonomous Engineer: The holy grail is an agent that can independently take a feature request from a Jira ticket, write the code, create the tests, respond to code review feedback, and deploy to production.
- Self-Healing Codebases: Future agents will not only write code but also monitor it in production, automatically identifying bugs or performance regressions and autonomously writing and deploying the fix, creating a fully closed-loop system.
Knowledge Management and Customer Support
While a softer domain, customer support offers a high volume of interactions that can be used to train adaptive agents. The key is translating qualitative feedback (e.g., customer satisfaction scores, resolution times) into a quantitative reward signal.
The goal is the evolving chatbot. A self-evolving agent can learn from each difficult case, updating its knowledge base or adjusting its dialogue strategy based on whether the customer was satisfied.
Key Players: While many developments are internal, established players like Intercom and Zendesk are heavily investing in LLM-based support bots. The well-funded consumer-facing agent Inflection AI's Pi is a key player to watch, as its emotionally intelligent conversational technology could be repurposed for enterprise customer support.
Future Directions:
- Proactive Support: Instead of waiting for a customer to ask a question, future agents will proactively identify users who are struggling (e.g., by observing their behavior via Amplitude) and offer assistance.
Business Process Automation
This is the largest and most disruptive opportunity: giving "brains" to static Robotic Process Automation (RPA) bots. The goal is to move from scripting repetitive tasks to defining high-level goals and letting the agent figure out how to achieve them.
Traditional RPA breaks when a UI element changes. An agent built on a vision-language model can adapt to these changes on the fly. The holy grail is goal-driven automation.
Key Players:
- Adept AI's ACT-1 model, which can execute tasks in a web browser, is the blueprint for this category; the team has since been acquired by Amazon.
- Dex directly embeds directly into browser workflows.
- Superhuman and Grammarly: deeper AI-automation inside daily email/doc workflows
- Sola.ai: early-stage automation tooling in the agentic BPA lane (emerging; closely watched).
Future Directions:
- Learning from Observation: The next generation of BPA agents will be trained by simply watching human operators perform a task. The agent will then generate its own internal policy for replicating that task and refine it over time based on feedback.
Field Insights From the Hackathon: What Builders Are Actually Doing
Our hackathon surfaced an unusually candid snapshot of what real developers, researchers, and operators gravitate toward when building self-evolving agents. Each team considered how they would implement the "outer loop" to their unique ideas. We are also able to see the aggregate patterns provide field evidence for where the ecosystem is headed—and where infrastructure demand is strongest.
Developers Choose Tools Based Functionality + DX
Many teams gravitated toward tools that minimized infrastructure overhead and maximized speed to "agent behavior." We saw rapid mainstreaming of:
- Weave + W&B for tracing and live diagnostics ("weave.init() was the fastest way to get visibility—we didn't have to do anything else," as one team put it).
- Firecrawl as the default "web API for AI," powering data ingestion in dozens of projects with minimal boilerplate.
- Harbor-style minimal APIs ("two hooks: how to install the agent, how to send a command") as the ideal developer ergonomics.
These observations validate a central lesson: DX is no longer a nice-to-have—it is a gating factor for agent adoption. The winners in agent infrastructure will be those who reduce the friction between idea, functioning agent, and an evaluable, improvable loop.
Community Is Emerging as a Core Moat for Agent Infrastructure
Several conversations highlighted a truth that is underweighted in most VCs' mental models: self-evolving systems require a continual stream of diverse tasks, corrections, and examples—and communities generate that data.
- Merrill (TerminalBench) emphasized that their ~1,000-member Discord community writing tasks is "central to the benchmark's difficulty, diversity, and relevance."
- Firecrawl's growth strategy relies on users building the first integration in each ecosystem, after which the team formalizes and maintains it. "That's the power of open source," as Firecrawl put it.
This aligns with an overlooked structural reality: self-evolution thrives where user communities continuously create new trajectories, corrections, and environments.
We Stay Cautiously Skeptic Toward Over-Opinionated Agent Frameworks
Multiple builders expressed hesitation about using heavy, prescriptive frameworks:
- "I haven't met anyone using [LangChain] at scale in production and loving the experience," one experienced engineer said.
- Teams gravitated instead toward PydanticAI, LangGraph, or bespoke orchestration, suggesting a preference for composable, low-level control.
This nuance strengthens your thesis that the "Agent OS" must remain flexible and low-imposition. The hackathon evidence supports a future where orchestration layers succeed only if they remain modular, interoperable, and minimally opinionated.
Sample Efficiency Is a Hard Bottleneck Builders Feel
A theme raised consistently in conversations: sample efficiency is the central bottleneck for self-improvement today. As one participant put it: "We can make an agent self-improve, but not cheaply."
In other words: Outer loops require thousands of trajectories, but most teams (at our hackathon and elsewhere) don't have the budget for that. Better sample efficiency (via distillation, reward models, offline RL, or clever evaluation harnesses) is the real unlock.
In our view, another attribute of the infrastructural winner will be one who makes self-evolution cheap.
Early Signals on Where Builders Think Self-Evolution Matters
- Cybersecurity & Red Teaming. Strong energy around agents that learn exploit strategies through feedback, multi-step reasoning, and environment interaction. Even early prototypes recognized that cybersecurity is a high-leverage environment for self-improving agents; in the future, this agentic framework may surpass human experts in developing long and complex attack chains.
- Accessible, Adaptive UI Interaction. Multiple teams built agents that learn how users navigate interfaces (via head tracking, voice, or nontraditional modalities). These agents sit directly on the event stream—clicks, focus changes, aborted actions, repeated errors—creating high-frequency interaction data that can be instrumented into feedback. With the right success metrics (task completion, time-to-completion, correction patterns), accessibility and adaptive UI become natural candidates for self-evolution.
- Self-Correcting Coding Agents. Several teams created repair agents or code-improvement loops. Combined with conversations about Claude Code and OpenAI's coding environments, the pattern is clear: Code is becoming the canonical proving ground for practical self-evolution because feedback is fast, cheap, and binary.
- Emotion, behavior, and personalization loops. Early projects around mood tracking, motivational companions, and video/voice agents were less mature technically but shared a common instinct: agents should tune themselves to people, not just tasks. Over time, these systems will convert implicit signals (engagement, response, sentiment) into explicit reward functions, driving self-evolution at the level of relationship and style rather than just task accuracy.
Where We Go From Here
Self-evolving agents are not a thought experiment anymore; they are a new computing stack coming into focus. The research frontier (Darwin Gödel Machine, Reflexion, STELLA, ACE) is converging with production primitives (agent OSs, MCP, vector memory, evaluators, learning environments) and real pull from domains like biomedicine, software, and business process automation. Our belief is simple: the next platform-defining companies will be the ones that turn the outer loop of learning into a product surface area, not an internal research project.
To this end, the Self-Evolving Agents Hackathon at AGI House is a controlled growth experiment. Our partners saw that stack recommendations (Weave, Weave evals, dashboards) drove user activation, while builders were incentivized to try new frameworks and tools–with many converting to long-term users. Especially under the self-evolving paradigm, hackathons are the proving ground where infra companies test activation, retention, and community-building strategies.
Our view is that we are still early in the self-evolution era, but not too early: the foundations exist (frontier models, MCP, RAG, agent OSs, observability), and the first real use cases are emerging in production. The opportunity now is to build the companies that treat learning as the core product feature—and in doing so, become the default way that software adapts to the world.
Acknowledgements
We're grateful to our sponsors—Weights & Biases, CoreWeave, and Firecrawl—for supporting the Self-Evolving Agents Hackathon and making this research possible. We'd also like to thank Sam Stowers from Weights & Biases for co-hosting the event and providing technical guidance to participants. Special thanks to Diya Sreedhar, Coco Xia, and Preethika Pavirala for their invaluable help in organizing and executing the event.
Our judges brought deep expertise across the AI stack: Siqi He (Founding Product Lead at Pika AI), Sam Stowers (AI Product Engineer at Weights & Biases), Nick Camara (Co-founder and CTO at Firecrawl), Oliver Wang (ML PhD at MIT Schwarzman College of Computing), Bohdan Kovalevskyi (Senior Engineer at OpenPipe), Angky William (Staff Engineer at CoreWeave), Jitesh Luthra (Head of Operations at Composio), Eric Ciarla (Co-founder and CMO at Firecrawl). We also want to give special thanks to Mark Mercer (Chief of Staff at Firecrawl) for coordinating and organizing our partnership. The event also featured insightful talks from Mike Merrill (AI NLP Postdoc at Stanford), Jason Qi (Research Scientist at Snorkel AI), and Bohdan Kovalevskyi (Senior Engineer at OpenPipe).
Finally, we extend our deepest gratitude to the entire AGI House community for creating a space where ambitious ideas meet execution. This hackathon brought together over 100 builders, researchers, and founders who dedicated their weekend to pushing the boundaries of what self-evolving agents can do. The energy, creativity, and technical depth demonstrated by every team—from early prototypes to production-ready systems—validated our belief that the best way to understand the future of AI is to build it together. Events like this don't just test technologies; they forge the communities and collaborations that will define the next era of intelligent systems.
About the Authors

Jessica Chen
Research Lead, Primary Contributor

Amy Zhuang
Operations & Research, Contributor

Alexa Orent
Operations Lead, Contributor

Rocky Yu
Founder and CEO, Contributor